K-Nearest Neighbors (KNN): A Comprehensive Guide
K-Nearest Neighbors (KNN): A Comprehensive Guide
K-Nearest Neighbors (KNN) is a versatile and intuitive supervised machine learning algorithm used for both classification and regression tasks. Its simplicity and effectiveness make it a popular choice for many applications.
How KNN Works
KNN operates on a fundamental principle: similar data points tend to have similar outcomes. The algorithm follows these steps:
- Store all available cases (training data).
- When given a new data point: a. Calculate the distance between the new point and all training points. b. Select the K nearest neighbors. c. For classification: assign the most common class among these neighbors. d. For regression: calculate the average value of the K neighbors.
Distance Calculation
The most common distance metric used in KNN is Euclidean distance, calculated as:
Where:
- is the distance between points and
- is the number of features
- and are the -th features of points and respectively
Other distance metrics like Manhattan distance or Minkowski distance can also be used.
Advantages and Disadvantages
| Advantages | Disadvantages |
|---|---|
| Simple to understand and implement | Computationally expensive for large datasets |
| No training phase required | Memory intensive (stores entire training set) |
| Can adapt to changes in data easily | Sensitive to irrelevant or redundant features |
| Effective for both classification and regression | Requires feature scaling for optimal performance |
| Non-parametric (makes no assumptions about data distribution) | Sensitive to imbalanced datasets |
Key Considerations
-
Choosing K: The value of K significantly impacts the model's performance.
- Small K: More sensitive to noise, but can capture fine-grained patterns.
- Large K: Smoother decision boundaries, but may miss important patterns.
- Odd K values are often used for binary classification to avoid ties.
-
Feature Scaling: KNN is sensitive to the scale of features. Always normalize or standardize your features before applying KNN.
-
Curse of Dimensionality: KNN's performance degrades in high-dimensional spaces. Use dimensionality reduction techniques if needed.
-
Imbalanced Datasets: KNN can be biased towards the majority class. Consider techniques like oversampling or undersampling to address this.
-
Computational Efficiency: For large datasets, consider using approximate nearest neighbor algorithms or data structures like KD-trees.
Implementing KNN with Scikit-learn
Here's an example of implementing KNN using scikit-learn, including some of the considerations mentioned above:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
# Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Scale the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create and train the KNN classifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_scaled, y_train)
# Make predictions on the test set
y_pred = knn.predict(X_test_scaled)
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# Print detailed classification report
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Predict a new sample
new_sample = np.array([[5.1, 3.5, 1.4, 0.2]])
new_sample_scaled = scaler.transform(new_sample)
prediction = knn.predict(new_sample_scaled)
print(f"\nPrediction for new sample: {iris.target_names[prediction[0]]}")
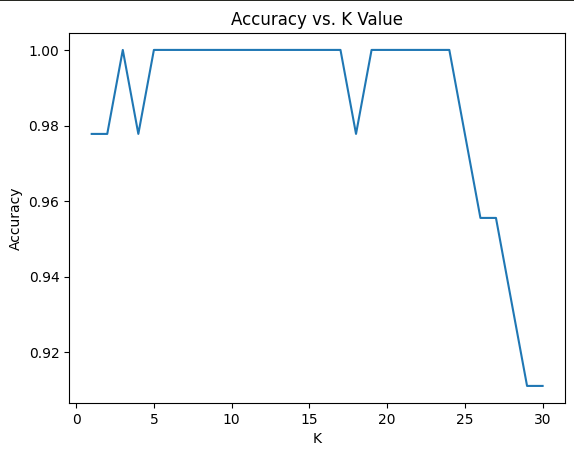
# Plot accuracy for different K values
k_values = range(1, 31)
accuracies = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_scaled, y_train)
accuracies.append(knn.score(X_test_scaled, y_test))
plt.plot(k_values, accuracies)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.title('Accuracy vs. K Value')
plt.show()
This code demonstrates:
- Loading and splitting the dataset
- Scaling features using StandardScaler
- Creating, training, and evaluating a KNN classifier
- Predicting a new sample
- Analyzing the impact of different K values on accuracy
Here's an implementation of the K-Nearest Neighbors algorithm without using scikit-learn. This implementation will cover the core functionality of KNN, including data loading, splitting, scaling, prediction, and evaluation. Note that this implementation may not be as optimized as scikit-learn's version, but it demonstrates the fundamental concepts.
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
# Load the Iris dataset
def load_iris():
from sklearn import datasets
iris = datasets.load_iris()
return iris.data, iris.target, iris.target_names
# Split the data into training and testing sets
def train_test_split(X, y, test_size=0.3, random_state=None):
if random_state is not None:
np.random.seed(random_state)
n_samples = len(X)
n_test = int(test_size * n_samples)
indices = np.random.permutation(n_samples)
test_indices = indices[:n_test]
train_indices = indices[n_test:]
return X[train_indices], X[test_indices], y[train_indices], y[test_indices]
# StandardScaler implementation
class StandardScaler:
def fit(self, X):
self.mean = np.mean(X, axis=0)
self.std = np.std(X, axis=0)
def transform(self, X):
return (X - self.mean) / self.std
def fit_transform(self, X):
self.fit(X)
return self.transform(X)
# KNN Classifier implementation
class KNeighborsClassifier:
def __init__(self, n_neighbors=5):
self.n_neighbors = n_neighbors
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
predictions = [self._predict(x) for x in X]
return np.array(predictions)
def _predict(self, x):
distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]
k_indices = np.argsort(distances)[:self.n_neighbors]
k_nearest_labels = [self.y_train[i] for i in k_indices]
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
def score(self, X, y):
predictions = self.predict(X)
return np.mean(predictions == y)
# Accuracy calculation
def accuracy_score(y_true, y_pred):
return np.mean(y_true == y_pred)
# Classification report
def classification_report(y_true, y_pred, target_names):
classes = np.unique(y_true)
report = ""
for i, class_name in enumerate(target_names):
precision = np.mean(y_pred[y_pred == i] == y_true[y_pred == i])
recall = np.mean(y_pred[y_true == i] == y_true[y_true == i])
f1 = 2 * (precision * recall) / (precision + recall)
support = np.sum(y_true == i)
report += f"{class_name:15s} {precision:.2f} {recall:.2f} {f1:.2f} {support}\n"
return report
# Main execution
X, y, target_names = load_iris()
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Scale the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Create and train the KNN classifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_scaled, y_train)
# Make predictions on the test set
y_pred = knn.predict(X_test_scaled)
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# Print detailed classification report
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names))
# Predict a new sample
new_sample = np.array([[5.1, 3.5, 1.4, 0.2]])
new_sample_scaled = scaler.transform(new_sample)
prediction = knn.predict(new_sample_scaled)
print(f"\nPrediction for new sample: {target_names[prediction[0]]}")
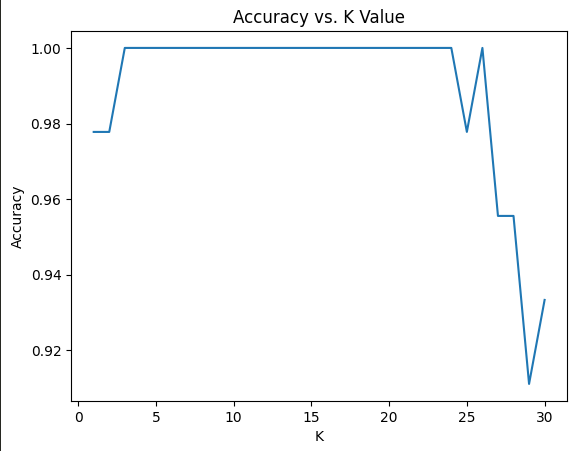
# Plot accuracy for different K values
k_values = range(1, 31)
accuracies = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_scaled, y_train)
accuracies.append(knn.score(X_test_scaled, y_test))
plt.plot(k_values, accuracies)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.title('Accuracy vs. K Value')
plt.show()
This implementation includes:
- A custom
load_iris()function (which still uses sklearn for data loading, as implementing this from scratch would be beyond the scope) - A custom
train_test_split()function - A
StandardScalerclass for feature scaling - A
KNeighborsClassifierclass implementing the KNN algorithm - Custom
accuracy_score()andclassification_report()functions
The main execution part remains similar to the scikit-learn version, but now it uses our custom implementations.
Note that this implementation is not optimized for large datasets and may be slower than scikit-learn's version. However, it demonstrates the core concepts of the KNN algorithm and the associated data preprocessing steps.
Conclusion
KNN is a powerful and intuitive algorithm that can be effective for many machine learning tasks. However, its performance heavily depends on the choice of K, proper feature scaling, and the characteristics of the dataset. By understanding these factors and applying appropriate preprocessing techniques, you can leverage KNN's strengths while mitigating its limitations.
Remember to always validate your model's performance and consider the specific requirements of your problem when deciding whether KNN is the right choice for your task.