What is Decision Tree
1. Introduction to Decision Trees
Definition and Basic Concept
Decision trees are a popular machine learning algorithm used for both classification and regression tasks. At their core, decision trees are a series of if-then statements that create a model to predict a target variable by learning decision rules inferred from training data.
The structure resembles an inverted tree, starting from a root node and branching down to leaf nodes. Each internal node represents a "test" on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label or a numerical value (in the case of regression).
Historical Background
The concept of decision trees has roots in management theory and operations research from the 1960s. However, their use in machine learning gained prominence in the 1980s with the development of algorithms like ID3 by Ross Quinlan.
Key milestones:
- 1960s: Early conceptual development in management decision-making
- 1975: ID3 algorithm introduced by Ross Quinlan
- 1984: CART (Classification and Regression Trees) developed by Breiman et al.
- 1993: C4.5 algorithm, an improvement on ID3, introduced
Applications in Various Fields
Decision trees have found applications across numerous domains due to their interpretability and versatility:
- Finance: Credit scoring, fraud detection, risk assessment
- Healthcare: Diagnosis support, treatment planning
- Marketing: Customer segmentation, churn prediction
- Environmental Science: Species identification, habitat modeling
- Manufacturing: Quality control, fault diagnosis
- Human Resources: Employee retention, performance prediction
2. Fundamentals of Decision Trees
Structure of a Decision Tree
- Root Node: The topmost node, representing the entire dataset and the first attribute for splitting.
- Internal Nodes: Nodes that test an attribute and branch further.
- Branches: Outcomes of a test, connecting nodes.
- Leaf Nodes: Terminal nodes that provide the final decision or prediction.
Types of Decision Trees
- Classification Trees: Used when the target variable is categorical. Each leaf represents a class label.
- Regression Trees: Used when the target variable is continuous. Each leaf represents a numerical value.
Key Terminology
- Splitting: The process of dividing a node into two or more sub-nodes based on a decision rule.
- Pruning: Removing branches of the tree to prevent overfitting.
- Information Gain: A measure of how much information a feature provides about the target variable.
- Gini Impurity: A measure of the probability of incorrect classification of a randomly chosen element.
- Entropy: A measure of the impurity or uncertainty in the data set.
Decision Boundaries in Decision Trees
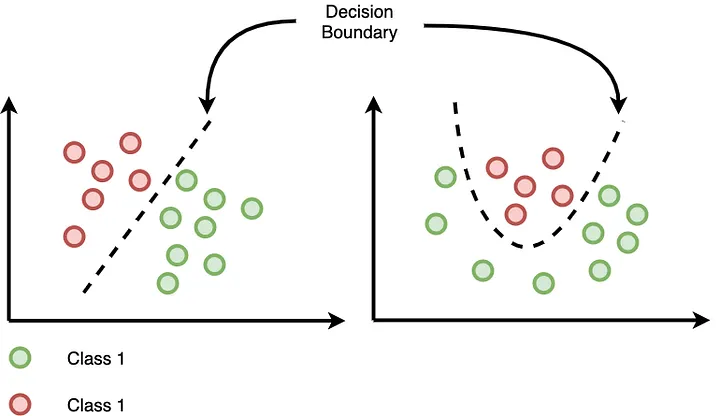
Decision trees are a popular machine learning algorithm used for both classification and regression tasks. From a decision boundary perspective, decision trees are particularly notable for their ability to create non-linear decision boundaries.
Key points about decision trees and decision boundaries:
- Non-linear boundaries: Unlike linear models like logistic regression, decision trees can create complex, non-linear decision boundaries. This allows them to fit more complex datasets that aren't linearly separable.
- Axis-parallel boundaries: The decision boundaries created by decision trees are always parallel to the feature axes. This is because each split in the tree is based on a threshold value for a single feature.
- Piecewise linear boundaries: The overall decision boundary of a decision tree is made up of multiple linear segments, creating a piecewise linear boundary. This allows the tree to approximate curved boundaries.
- Hierarchical partitioning: Decision trees partition the feature space into rectangular regions through a hierarchical process. Each internal node of the tree represents a split of the feature space.
- Flexibility: The flexibility of decision trees in creating complex boundaries is both an advantage and a potential drawback. It allows them to fit complex patterns but can also lead to overfitting.

Advantages of decision trees from a boundary perspective:
- Can create complex, non-linear decision boundaries
- No assumptions about the shape or distribution of the data
- Can handle both linear and non-linear relationships
Disadvantages:
- Prone to overfitting, creating overly complex boundaries that don't generalize well
- Axis-parallel splits may be inefficient for some types of boundaries
- Instability - small changes in data can lead to very different boundaries
To address these issues, techniques like pruning and ensemble methods (e.g., random forests) are often used. These help to create more robust and generalizable decision boundaries.
3. How Decision Trees Work
Decision Tree Algorithm Overview
The general approach for building a decision tree involves:
- Selecting the best attribute to split the data
- Making that attribute a decision node and breaking the dataset into smaller subsets
- Repeating this process recursively for each child until a stopping condition is met
Splitting Criteria
-
Gini Impurity:
- Measures the probability of incorrect classification
- Formula: Gini = 1 - Σ(pi^2), where pi is the probability of an item being classified to a particular class
- Used in the CART algorithm
-
Entropy and Information Gain:
- Entropy measures the impurity or uncertainty in the dataset
- Formula: Entropy = -Σ(pi * log2(pi))
- Information Gain = Entropy(parent) - [Weighted Sum of Entropy(children)]
- Used in algorithms like ID3 and C4.5

- Variance Reduction:
- Used for regression trees
- Aims to minimize the variance in the target variable within each subset
Recursive Partitioning Process
- Start with the entire dataset at the root node
- For each feature: a. Calculate the impurity measure (Gini, Entropy, or Variance) b. Calculate the potential information gain from splitting on this feature
- Select the feature that provides the highest information gain
- Create decision nodes based on the selected feature
- Split the dataset according to the feature values
- Repeat the process for each subset until a stopping criterion is met
4. Building a Decision Tree
Feature Selection
- Importance of choosing relevant features
- Techniques for feature selection (correlation analysis, mutual information, etc.)
- Handling high-dimensional data
Determining the Best Split
- Evaluating all possible splits
- Optimizing for computational efficiency
- Handling continuous vs. categorical features
Stopping Criteria and Tree Pruning
- Maximum depth of the tree
- Minimum number of samples required to split an internal node
- Minimum number of samples in a leaf node
- Pre-pruning vs. post-pruning techniques
5. Types of Decision Tree Algorithms
ID3 (Iterative Dichotomiser 3)
- Developed by Ross Quinlan in 1986
- Uses Information Gain as the splitting criterion
- Works with categorical attributes only
- Builds the tree to its maximum depth
- Prone to overfitting, especially with noisy data
C4.5 and C5.0
-
C4.5: An improvement over ID3, also by Ross Quinlan
- Can handle both continuous and categorical attributes
- Uses Gain Ratio instead of Information Gain to address bias towards attributes with many values
- Implements pruning to reduce overfitting
- Can handle missing values
-
C5.0: A commercial version of C4.5 with improvements
- Faster and more memory efficient than C4.5
- Supports boosting for improved accuracy
- Generates smaller decision trees
CART (Classification and Regression Trees)
- Developed by Breiman et al. in 1984
- Can be used for both classification and regression tasks
- Uses Gini impurity for classification and variance reduction for regression
- Produces binary trees (each node has exactly two branches)
- Implements cost-complexity pruning to prevent overfitting
6. Advantages of Decision Trees
Interpretability and Explainability
- Easy to understand and interpret, even for non-experts
- Can be visualized, making it easy to explain decisions
- Follows human decision-making logic, enhancing trust in the model
Handling Both Numerical and Categorical Data
- Can work with mixed data types without extensive preprocessing
- Automatically handles feature scaling issues
- Can capture non-linear relationships in the data
Minimal Data Preparation Required
- Does not require normalization or standardization of features
- Can handle missing values effectively
- Robust to outliers in the input space
Ability to Handle Missing Values
- Can create surrogate splits to handle missing data during both training and prediction
- Multiple strategies available: imputation, separate branch for missing values, or using other correlated features
7. Limitations and Challenges
Overfitting and How to Address It
- Tendency to create overly complex trees that don't generalize well
- Solutions:
- Pruning (pre-pruning and post-pruning)
- Setting minimum samples per leaf
- Limiting tree depth
- Using ensemble methods like Random Forests
Instability and Sensitivity to Small Changes in Data
- Small variations in the data can result in a completely different tree being generated
- This instability can affect model reliability and interpretability
- Mitigated by using ensemble methods or cross-validation techniques
Biases in Feature Selection
- Bias towards features with more levels when using impurity-based splitting criteria
- Can be addressed by using appropriate splitting criteria (e.g., Gain Ratio instead of Information Gain)
Limitations in Capturing Complex Relationships
- Difficulty in representing certain types of relationships (e.g., XOR problems)
- May require very deep trees to approximate some functions, leading to overfitting
- Ensemble methods or more advanced tree algorithms can help overcome these limitations
8. Decision Tree Optimization Techniques
Pre-pruning and Post-pruning
- Pre-pruning: Stopping tree growth before it fully classifies the training set
- Methods: maximum depth, minimum samples per leaf, minimum impurity decrease
- Post-pruning: Building the full tree and then removing branches
- Methods: reduced error pruning, cost complexity pruning
Hyperparameter Tuning
- Key hyperparameters to tune:
- Maximum depth
- Minimum samples per leaf
- Minimum samples for split
- Maximum number of features
- Techniques for tuning:
- Grid search
- Random search
- Bayesian optimization
Ensemble Methods
- Random Forests:
- Building multiple trees on random subsets of data and features
- Aggregating predictions to reduce overfitting and improve stability
- Gradient Boosting:
- Sequential building of trees, each correcting errors of the previous ones
- Examples: XGBoost, LightGBM, CatBoost
9. Evaluating Decision Tree Performance
Metrics for Classification Trees
- Accuracy: Overall correctness of predictions
- Precision, Recall, F1-Score: Metrics for imbalanced datasets
- ROC-AUC: Area under the Receiver Operating Characteristic curve
- Confusion Matrix: Detailed breakdown of correct and incorrect classifications
Metrics for Regression Trees
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE)
- R-squared (Coefficient of Determination)
Cross-validation Techniques
- K-Fold Cross-Validation
- Stratified K-Fold for imbalanced datasets
- Leave-One-Out Cross-Validation
- Time Series Cross-Validation for temporal data
10. Decision Trees in Practice
Implementation in Popular Libraries
- Scikit-learn: Widely used Python library for machine learning
- R's rpart package: Implementation of CART algorithm
- XGBoost, LightGBM: Advanced gradient boosting libraries
- Comparison of implementations and their specific features
Case Studies and Real-World Applications
- Credit scoring models in finance
- Disease diagnosis in healthcare
- Customer churn prediction in telecommunications
- Detailed examples with code snippets and interpretation
Best Practices for Using Decision Trees
- Feature engineering and selection
- Handling imbalanced datasets
- Interpreting and visualizing decision trees
- When to use decision trees vs. other algorithms
11. Advanced Topics
Oblique Decision Trees
- Unlike traditional decision trees that split data using axis-parallel lines, oblique decision trees use linear combinations of features to create splits.
- This approach allows for more flexible and potentially more accurate decision boundaries.
- Techniques involve linear discriminant analysis or using hyperplanes for splitting.
Fuzzy Decision Trees
- Incorporate fuzzy logic to handle uncertainty and vagueness in data.
- Use membership functions to assign degrees of belonging to different classes.
- Useful in situations where the boundaries between classes are not well-defined.
Decision Trees for Multi-output Problems
- Capable of handling multiple target variables simultaneously.
- Each leaf node predicts a vector of outputs rather than a single value or class.
- Useful in applications like multi-label classification and multi-target regression.
12. Comparison with Other Machine Learning Algorithms
Decision Trees vs. Linear Models
- Decision trees can model non-linear relationships, while linear models assume a linear relationship between features and the target variable.
- Linear models are generally more interpretable for continuous data, but decision trees offer better interpretability for complex, rule-based decisions.
Decision Trees vs. Neural Networks
- Neural networks can capture complex patterns and interactions between features but require more data and computational resources.
- Decision trees are faster to train and easier to interpret but may struggle with very high-dimensional or complex feature spaces.
When to Choose Decision Trees
- When interpretability and explainability are crucial.
- When the dataset contains both categorical and numerical features.
- When the data has missing values or requires minimal preprocessing.
13. Future Trends and Research Directions
Improvements in Scalability and Efficiency
- Research is focused on developing algorithms that can handle large datasets more efficiently.
- Parallel processing and distributed computing techniques are being explored to speed up tree construction.
Integration with Other AI Techniques
- Combining decision trees with other machine learning models to create hybrid systems.
- Integration with deep learning techniques for feature extraction followed by decision tree classification.
Ethical Considerations in Decision Tree Usage
- Ensuring fairness in decision-making processes, especially in sensitive areas like finance and healthcare.
- Addressing biases that may be inherent in the training data or introduced by the model itself.
14. Conclusion
Recap of Key Points
- Decision trees are versatile tools for both classification and regression tasks, offering clear interpretability and flexibility in handling various data types.
- They have certain limitations, such as overfitting and sensitivity to data changes, which can be mitigated through techniques like pruning and ensemble methods.
The Role of Decision Trees in the Machine Learning Landscape
- Despite their simplicity, decision trees remain a foundational tool in machine learning due to their ease of use, interpretability, and ability to serve as building blocks for more complex models like Random Forests and Gradient Boosting Machines.
- As research continues to address their limitations, decision trees will likely remain a vital component of the machine learning toolkit.
This concludes the detailed content agenda for writing about decision trees. Each section provides a comprehensive overview of key aspects of decision trees, from basic concepts to advanced topics and future trends. This structure should help you create an informative and engaging piece on decision trees.