RAG (Retrieval Augmented Generation)
Retrieval-augmented generation (RAG) is an innovative AI framework that enhances the capabilities of large language models (LLMs) by grounding them on external sources of knowledge. This approach addresses two key limitations of traditional LLMs: their tendency to generate inconsistent or inaccurate information, and their reliance on potentially outdated training data.
How RAG Works
RAG operates in two main phases:
-
Retrieval: Algorithms search for and retrieve relevant information snippets based on the user's prompt or question.
-
Generation: The LLM uses the retrieved information to generate a response.
This process can be likened to an "open-book exam" approach, where the model browses through content to answer questions rather than relying solely on its internal knowledge.
Retrieval-augmented generation (RAG) combines the power of large language models (LLMs) with external knowledge retrieval to produce more accurate and up-to-date responses. Here's an overview of the RAG architecture:
RAG Architecture Components
- User Input: The process begins with a user query or prompt.
- Embedding Model: Converts the user input and documents in the knowledge base into vector representations.
- Knowledge Base: A collection of documents, articles, or other relevant information sources.
- Vector Database: Stores the vector embeddings of documents for efficient retrieval.
- Retriever: Searches the vector database to find relevant documents based on the user query.
- Reranker (optional): Evaluates and scores retrieved documents for relevance.
- Context Builder: Combines the most relevant retrieved information with the original query.
- Large Language Model (LLM): Generates the final response using the augmented context.
RAG Workflow
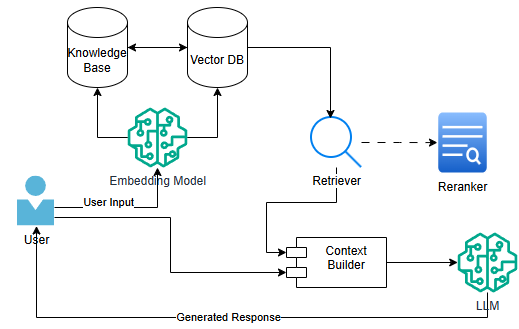
- The user submits a query.
- The embedding model converts the query into a vector representation.
- The retriever searches the vector database for similar document embeddings.
- Relevant documents are retrieved and optionally reranked.
- The context builder combines the original query with the retrieved information.
- The augmented context is sent to the LLM for processing.
- The LLM generates a response based on the provided context and its own knowledge.
- The final answer is returned to the user.
Key Advantages
- Improved Accuracy: Grounding responses in external, up-to-date information.
- Reduced Hallucinations: Mitigating the risk of generating incorrect or fabricated information.
- Transparency: Allowing users to verify sources and fact-check responses.
- Flexibility: Easily updating the knowledge base without retraining the entire model.
- Cost-Effectiveness: Providing domain-specific knowledge without extensive fine-tuning.
LlamaIndex
LlamaIndex is a powerful and flexible data framework designed to connect large language models (LLMs) with custom data sources. Here are the key features and functionalities of LlamaIndex:
Core Features
Data Ingestion and Indexing: LlamaIndex supports over 160 data sources and formats, allowing easy loading of unstructured, semi-structured, and structured data (APIs, PDFs, documents, SQL, etc.).
Querying and Retrieval: Utilizes advanced retrieval techniques to provide optimal context to LLMs, preventing hallucinations.
Flexibility and Customization: Offers endless customization layers for AI engineers of all levels, from beginners to experts.
Agent Architecture: Provides agent capabilities to break down complex questions, plan tasks, and call APIs.
Key Components

- Embedding Model: Converts user input and knowledge base documents into vector representations.
- Vector Database: Stores vector embeddings of documents for efficient retrieval.
- Retriever: Finds relevant documents based on user queries.
- Context Builder: Combines retrieved information with the original query.
- Large Language Model (LLM): Generates final responses using the augmented context.
Advantages
- Production Readiness: Offers state-of-the-art RAG algorithms and robust integrations.
- Community Support: Has an active community providing various connectors, tools, and datasets.
- Integration Options: Connects with 40+ vector stores, numerous LLMs, and 160+ data sources.
- Open Source: Available on GitHub with active development and support.
Key Benefits
- Simplified Data Connection: Easily connect LLMs to various data sources.
- Enhanced Accuracy: Improve response accuracy by grounding LLMs in custom data.
- Scalability: Handle large datasets efficiently with advanced indexing techniques.
- Customization: Tailor the framework to specific use cases and requirements.
- Continuous Learning: Keep AI applications up-to-date with the latest information.
Vector Database
Vector databases are specialized storage systems designed to efficiently handle and query high-dimensional vector data, primarily used in AI and machine learning applications for fast and accurate data retrieval. Here's an overview of vector databases:
Key Features
- Vector Embeddings Storage: Vector databases store information as vectors, which are numerical representations of data objects, also known as vector embeddings.
- Similarity Search: They enable semantic search and similarity matching based on the meaning and context of data, rather than just keyword matching.
- Multimodal Support: Vector databases can handle multiple data types (text, images, audio, video) by representing them as vectors in the same multidimensional space.
- Scalability: They are designed to manage large volumes of high-dimensional vector data efficiently.
- Indexing: Vector databases employ specialized indexing structures and algorithms to facilitate fast retrieval of similar vectors.
How Vector Databases Work
- Data Ingestion and Vectorization: Raw data is converted into vector embeddings using embedding models.
- Vector Storage: The embeddings are stored in an optimized format.
- Vector Indexing: Specialized indexing techniques are applied to organize the vectors for efficient retrieval.
- Similarity Search: When queried, the database uses algorithms like Approximate Nearest Neighbor (ANN) search to find the most similar vectors.
Advantages Over Traditional Databases
- Semantic Understanding: Vector databases can capture and query based on the meaning of data, not just exact matches.
- Efficient Similarity Search: They enable fast and accurate retrieval of semantically similar data points.
- Multimodal Capabilities: Vector databases can handle and relate different types of data in a unified way.
- AI Integration: They are optimized for AI and machine learning workflows, particularly in supporting generative AI applications.
Types of Vector Databases
-
Open-source Vector Databases
- Milvus Standalone
- Weaviate Weaviate Tutorial
- Qdrant
- Chroma Github
-
Cloud-based Managed Vector Databases
- Pinecone
- Vespa
- Zilliz Cloud (based on Milvus)
-
Hybrid Vector Databases
- Elasticsearch with vector search capabilities
- PostgreSQL with vector extensions (e.g., pgvector)
-
In-memory Vector Databases
-
Graph-based Vector Databases
- Neo4j with vector indexing
-
Distributed Vector Databases
- Milvus
- Vespa
-
Specialized Vector Databases
-
Vald (for high-dimensional vectors)
-
VectorDB with LlamaIndex Example
-
Pinecone
from llama_index.vector_stores import PineconeVectorStore from llama_index.core import StorageContext, VectorStoreIndex vector_store = PineconeVectorStore(...) storage_context = StorageContext.from_defaults(vector_store=vector_store) index = VectorStoreIndex.from_documents(documents, storage_context=storage_context) -
Milvus
from llama_index.core import VectorStoreIndex, StorageContext from llama_index.vector_stores.milvus import MilvusVectorStore # Initialize Milvus vector store vector_store = MilvusVectorStore( uri="localhost:19530", # Milvus server URI collection_name="my_collection", # Name of the collection to use dim=1536, # Embedding dimension (depends on the embedding model used) overwrite=True # Whether to overwrite existing collection ) # Create StorageContext storage_context = StorageContext.from_defaults(vector_store=vector_store) # Create index from documents documents = [...] # Insert your list of documents here index = VectorStoreIndex.from_documents( documents, storage_context=storage_context ) # Execute a query query_engine = index.as_query_engine() response = query_engine.query("Your question here") print(response)
RAG Evaluation
Evaluating a Retrieval-Augmented Generation (RAG) system is crucial for ensuring its performance and identifying areas for improvement. Here's an overview of how to evaluate RAG:
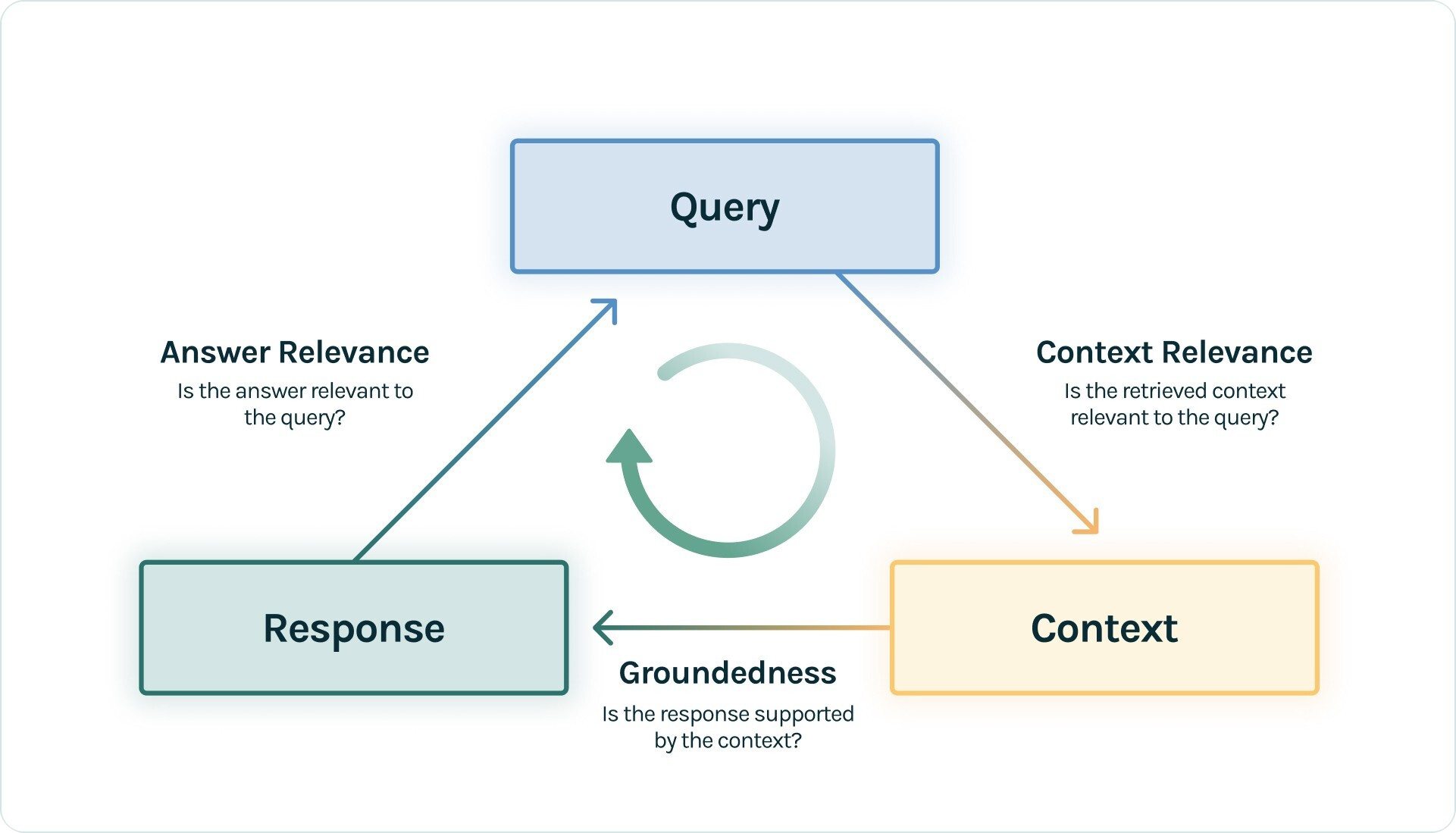
Source : TrueLens
Key Components to Evaluate
- Retriever: Assesses how well relevant information is retrieved from the knowledge base.
- Generator: Evaluates the quality of the generated responses using the retrieved context.
- End-to-End Performance: Measures the overall effectiveness of the RAG system.
Evaluation Metrics
Retrieval Evaluation
- Precision: Measures the quality of retrieved results.
- Recall: Assesses the completeness of retrieved results.
- Mean Reciprocal Rank (MRR): Evaluates how quickly the first relevant document is retrieved.
- Mean Average Precision (MAP): Provides a comprehensive evaluation combining precision and rank of relevant documents.
Response Evaluation
- Faithfulness (Groundedness): Checks if the generated response is factually accurate and based on the retrieved documents.
- Answer Relevancy: Measures how well the response addresses the user's query.
- Context Relevance: Evaluates the relevance of retrieved documents to the query.
Evaluation Methods
-
Automated Metrics:
- BLEU, ROUGE, METEOR: These metrics are used to evaluate the quality of generated text by comparing it to reference answers.
- Embedding-based evaluations: Used for measuring semantic similarity between generated and reference responses.
-
LLM-as-Judge:
- This approach uses large language models to assess the quality, relevance, and faithfulness of generated responses.
- It can provide more nuanced evaluations than simple automated metrics.
-
Human Evaluation:
- Involves human raters assessing the quality of responses.
- Considered the gold standard but can be time-consuming and expensive.
-
Framework-Specific Evaluators:
- RAGAS: Offers metrics like Average Precision (AP) and Faithfulness.
- ARES: Focuses on Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (NDCG).
- Arize: Emphasizes Precision, Recall, and F1 Score.
- TruLens: Specializes in domain-specific optimizations and detailed metrics for retrieval components.
-
Component-Specific Evaluators:
- Retriever Evaluation: Assesses the quality and relevance of retrieved documents.
- Generator Evaluation: Focuses on the quality and accuracy of the generated responses.
-
End-to-End Evaluators:
- These assess the overall performance of the RAG system, considering both retrieval and generation aspects.
-
Custom Evaluators:
- Tailored metrics and evaluation methods designed for specific use cases or domains.
Best Practices
- Establish Baselines: Set performance benchmarks using standard metrics.
- Continuous Monitoring: Regularly evaluate your RAG system to track performance over time.
- Use Multiple Metrics: Combine various metrics for a comprehensive evaluation.
- Tune Hyperparameters: Experiment with different settings like chunk size, overlap, and number of retrieved documents.
- Re-Ranking Techniques: Implement re-ranking to improve retrieval quality.
- Custom Evaluation: Develop domain-specific metrics for specialized use cases.