
Build a Large Language Model from Scratch

Introduction
Anyone interested in artificial intelligence and natural language processing (NLP) has likely wondered about the internal workings and mechanisms of large language models (LLMs). With the rise of models like the GPT series, research and development in this field have accelerated significantly. However, building such models from scratch is no simple task. Build a Large Language Model from Scratch by Sebastian Raschka serves as a practical guide to taking on this challenge.
Overview
This book is aimed at readers who already have a foundational understanding of machine learning and deep learning. It explains how to implement an LLM from the ground up, focusing on building a Transformer-based model similar to GPT-2 using PyTorch and guiding readers through training and fine-tuning processes step by step.
The book covers the following key topics:
- Understanding Transformer Architecture
- Multi-head attention and feedforward networks
- Layer normalization and dropout techniques
- Implementing a Model with PyTorch
- Tokenization and data processing
- Model construction and training
- Pretraining and Fine-tuning
- Training a model using large-scale text datasets
- Fine-tuning for specific tasks
- Optimization and Performance Enhancement
- Techniques for improving training efficiency
- Model compression strategies
This structure balances theoretical explanations with hands-on coding exercises, allowing readers to learn by implementing the concepts themselves.
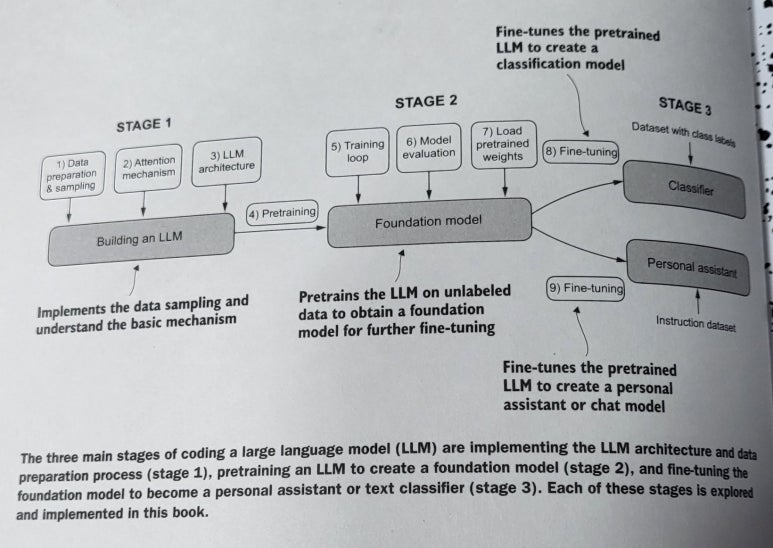
Strengths and Features
The greatest strength of this book lies in its well-balanced combination of theory and practice. Rather than merely explaining Transformer concepts, it provides clear, practical code examples to help readers implement them. Furthermore, it covers the entire process from data preparation to deploying a fully trained model, making it highly beneficial for developers and researchers eager to work with LLMs.
Key features of the book include:
- Code-driven learning: Each step is accompanied by PyTorch-based code, making implementation easier.
- Incorporation of the latest research: The book integrates recent advancements in Transformer models.
- Optimization and performance strategies: It addresses common training challenges and solutions.
Making It Easier to Understand
This book is particularly useful for readers with prior experience in deep learning and PyTorch. Since it involves building a Transformer model from scratch, familiarity with PyTorch will make the learning process smoother. While training large-scale LLMs requires substantial computational resources (such as GPUs or TPUs), readers can still gain a deep understanding of the concepts by working through the examples and code provided.
Conclusion
Build a Large Language Model from Scratch is an essential read for developers and researchers looking to construct LLMs on their own. By leveraging PyTorch, it walks readers through the entire process, from data preprocessing to model optimization. Though the technical barrier is relatively high, this book serves as an excellent hands-on guide for those eager to deepen their understanding of deep learning and NLP.
Recommended for:
- NLP researchers who want to build an LLM from scratch
- Developers interested in training Transformer models using PyTorch
- Anyone seeking a deeper understanding of LLM internals
Are you ready to take on the challenge of building an LLM yourself? This book will guide you every step of the way!
